

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在Spark中,假设lines是一个DStream对象,filter语句可以过滤掉80%的数据,针对以下两个语句说法正确的是:()。X:lines.filter(...).groupByKey(...)
A.X比Y的性能更高
B.X比Y的性能更低
C.X和Y和性能一样
D.无法确性X和Y的性能差异
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.X比Y的性能更高
B.X比Y的性能更低
C.X和Y和性能一样
D.无法确性X和Y的性能差异
答案
 更多“在Spark中,假设lines是一个DStream对象,filter语句可以过滤掉80%的数据,针对以下两个语句说法”相关的问题
更多“在Spark中,假设lines是一个DStream对象,filter语句可以过滤掉80%的数据,针对以下两个语句说法”相关的问题
第1题
A.dgvData.DataSource=ds;dgvData.DataMember=ds.Tables["table1"];
B.dgvData.DataMember=ds;
C.dgvData.DataSource=newDataView(ds.Tables["table1"]);
D.dgvData.DataSource=ds.Tables["table1"];dgvData.DataMember=ds;
第5题
一个10kg的卫星,在8000km半径的轨道上环绕地球,每小时转一周。(1)假定波尔的角动量假设可用于卫星,犹如它用于氢原子中的电子那样,试求这卫星的轨道量子数;(2)从波尔的第一条假设和牛顿万有引力定律,证明地球卫星的轨道半径直接与量子数的平方成正比,即r=k·n2,式中k是比例常数; (3)利用本题(2)的结果,假设某卫星轨道和它的下一个“容许”轨道都存在,试求这两个相邻轨道间的距离。
第6题
本题要用到WAGE2.RAW中的数据。
(i)考虑一个标准的工资方程
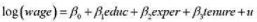
表述虚拟假设:多一年工作经历与在现在的岗位上多工作一年对log(wage) 具有相同影响。
(ii)在5%的显著性水平上,相对于双侧对立假设,通过构造一个95%的置信区间来检验第(i)部分中的虚拟假设。你得到的结论是什么?























